Googlebotからのページのリクエストに対し、ユーザ向けと異なるコンテンツを返す処理は「クローキング」と言われるガイドライン違反に該当するが、「会員向けコンテンツの一部をGooglebotに提供する」こと(=サンプリング)は、適切に対応すればクローキングとはみなされない。
この適切な対応というのが、Flexible Sampling(旧First Click Free)である。
ペイウォールコンテンツとは
定期購読コンテンツはペイウォール方式を採用するのが通例であるため、定期購読を利用していないユーザーはコンテンツにアクセスできない。
ペイウォールの向こう側に良質なコンテンツがあっても、そのことを知らないユーザーは、無料コンテンツを提供する別のサイトに移ってしまう傾向が強いことが評価を行う中で明らかになっている。
定期購読コンテンツの有益さがユーザーに認識されていなければ、定期購読を申し込んでもらうことは容易ではなく、実際、定期購読が必要なサイトを敬遠するユーザーが一定数いることが、Google が行った調査の結果からわかっている。
したがって、定期購読コンテンツが有益であることをユーザーに知ってもらうために、コンテンツの一部を無料サンプルとして提供することが不可欠である。
ペイウォール方式を採用するサイトには、ページに新しい構造化データを追加することを強く推奨する。
この構造化データを追加していないと、ペイウォールがクローキングの一種と解釈され、ページが検索結果から削除される可能性がある。
First Click Free とは
会員登録しないと読めないニュース記事等(ペイウォールコンテンツ)に関して、Google検索から該当ページに入った場合は、1日3本まではその記事ページを全部読むことが出来る仕組みのこと。
メディア側が検索エンジンにしっかりとインデックスさせたいあまり、Googleには記事全部を見させておきながら、ユーザーには記事の一部しか見せないとなるとクローキング扱いされてしまうため、こういったFCFの処置が施されていた。
クローキングとは
ユーザーに配信するコンテンツと Googlebot がクロールするコンテンツを異なるものにする行為。スパマーがよく使う手は、検索結果の掲載順位を操作する目的で、検索エンジンに対してはその評価が高そうなコンテンツ(たとえば健康に良い料理のレシピ)を表示する一方、ユーザーに対しては別のコンテンツ(たとえばダイエット薬の販売ページ)を表示するという方法。こうした「おとり」手法は、期待していたのと違うコンテンツを見せられるという不快感をユーザーを与える。
Flexible Sampling とは
Flexible Samplingとは、定期購入とペイウォールコンテンツの構造化データにしたがって有料コンテンツをマークアップすることで、有料の記事等をGooglebotに見せる一方でユーザーには課金や登録を求めるページを表示することが可能になる技術。
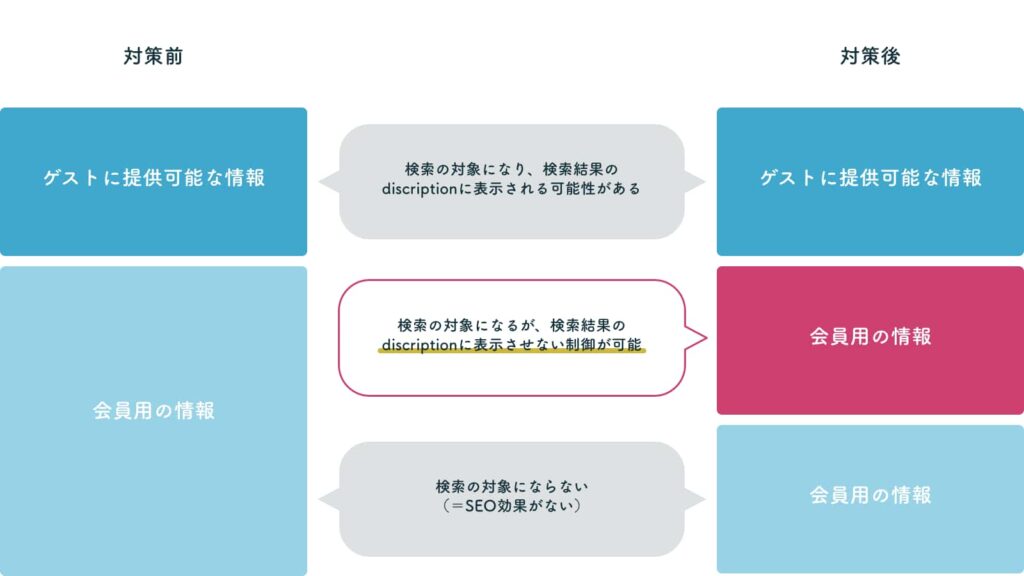
Flexible Sampling には2つの方法があるが、まずは大前提としてペイウォールコンテンツであることを構造化データを使用してGoogleに伝えなければならない。
ペイウォールでコンテンツを提供する場合は、隠す方の<div>にclass設定を行う。class名は任意で問題ないが、JSON-LDのcssSelectorではそのclass名を記述する必要がある。
ユーザーに課金させるサブスクリプション型のサービスには主に、
①定期購読(会員制など)
②コンテンツ課金(記事ごとに課金するなど)
の2種類の課金形態が考えられる。
この双方に対応できるよう、フレキシブルサンプリングには2種類の実装方法が存在する。
メータリング
メータリング は、従来の FCF のように一定数の記事を検索ユーザーが無条件で読むことを許可する構成。
しかし FCF とは異なり、読める記事の数は定められておらず、パブリッシャーが自由に設定可能。
1日3記事まででもいいし、1か月に10記事まででも構わない。
とはいえ、購読率の観点から Google は月単位の制限を推奨している。
具体的には、1か月に6〜10記事程度の範囲で、最初は10記事から始めるといい。
もちろん、これは単なる推奨であるため、1日ごとの制限がいいと思えば1日ごとにできるし、1か月に5記事からスタートすることにもまったく問題はない。
技術的に可能であれば、ベースは1か月に10記事だけれど、頻繁に訪問するユーザーには購読を促すために1か月に5記事に減らしてもいいだろう。
リードイン
リードインの場合は、記事の一部(たとえば冒頭の数文)のみを表示する。
これによりユーザーは、定期購読コンテンツの質の高さを体験できる。
完全にブロックされているページとの比較で考えれば、リードインの方がコンテンツの有用性や価値を実感しやすいことは明らか。
メータリング よりも リードイン のほうが自社サイトでは機能すると判断するのであれば、リードイン 方式を採用するといいだろう。
構造化データで Flexible Sampling を実装
ペイウォール コンテンツであることを Google に伝えるには、構造化データを設定する。
ウェブサイトのコンテンツを定期購入制で提供している場合や、コンテンツへのアクセスに登録が必要となっている場合、そうしたコンテンツをインデックスに登録するには以下の手順を行う。
schema.org の CreativeWork のプロパティを追加した NewsArticle でマークアップする。
- クラス名を追加し、ページの各ペイウォール セクションを囲む。次に例を示す。
<body>
<p>This content is outside a paywall and is visible to all.</p>
<div class="paywall">This content is inside a paywall, and requires a subscription or registration.</div>
</body>- NewsArticle 構造化データを追加。
- JSON-LD 構造化データ(ハイライト表示された部分)を NewsArticle 構造化データに追加。
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://example.org/article"
},
(...)
"isAccessibleForFree": "False",
"hasPart": {
"@type": "WebPageElement",
"isAccessibleForFree": "False",
"cssSelector": ".paywall"
}
}複数のペイウォール セクションがある場合
ページに複数のペイウォール セクションがある場合は、クラス名を配列として追加する。
ページにペイウォール セクションがある場合の例を次に示す。
<body>
<div class="section1">This content is inside a paywall, and requires a subscription or registration.</div>
<p>This content is outside a paywall and is visible to all.</p>
<div class="section2">This is another section that's inside a paywall, and requires a subscription or registration.</div>
</body>複数のペイウォール セクションがある NewsArticle 構造化データの例を、次に示す。
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://example.org/article"
},
(...)
"isAccessibleForFree": "False",
"hasPart": [
{
"@type": "WebPageElement",
"isAccessibleForFree": "False",
"cssSelector": ".section1"
}, {
"@type": "WebPageElement",
"isAccessibleForFree": "False",
"cssSelector": ".section2"
}
]
}Flexible Sampling とページネーション
ページネーションされているコンテンツでリードインを利用し、1ページ目の途中までをユーザーにログイン不要で閲覧させたい場合、2種類の対応が考えられる。
1つ目は、Googlebotにはそれぞれのページを全て見せ、ユーザーにはページネーションの全ページにおいて1ページ目の途中までのコンテンツを返すというやり方。
2つ目は、ViewAllページを作成してページネーションの全ページからcanonicalを当て、GooglebotにはViewAllの全コンテンツ、ユーザーにはViewAllの一部を返すという方法。
Googleはこのどちらの対応を行っても問題ないと認めている。
Flexible Sampling のSEO効用
Flexible Sampling を実装することによるSEO的な効用には以下が考えられる。
メリット
- ユーザーには課金させながらGoogleには全コンテンツを評価対象に入れさせることができる
- 構造化データによって有料コンテンツを認識すると、その部分はスニペット(検索結果におけるタイトル, 説明文など)に使用されない
デメリット
- 実装コストが一定かかる
- マークアップの失敗によってガイドライン違反判定されるリスクがある