Webページがブラウザに表示されるまでに何が起こるのか?
URLを解読する
ユーザーがURLを入力してEnterを押すと、ブラウザはまず入力されたURLの解読を始める。
URLを分解して、「プロトコル」と「ドメイン名」と「パス名」が何であるかを調べる。
https://koooooootalogic.tech/上記のURLの場合、https がプロトコル、koooooootalogic.techがドメイン名、/がパス名となる。
| プロトコル | https |
| ドメイン名 | koooooootalogic.tech |
| パス名 | / |
もしプロトコルの記述がなかったり有効なドメインではなかった場合、ブラウザは入力されたテキストをブラウザのデフォルトの検索エンジンに渡す。
HSTSリストを調べる
HSTS(HTTP Strict Transport Security)とは、ユーザーが http でアクセスしようとしてきたとき、ブラウザが自動で https に置き換えてアクセスしてくれる機能のこと。
つまるところ、http でアクセスしてきたユーザーを中間者攻撃から守るための仕組み。
一般的にSSL化したWebサイトでは、ユーザーがhttpでアクセスしてきても、httpsの方に強制的に遷移させるために、301リダイレクト( Moved Permanently ) 設定が行われている。

①httpでリクエストしてきたユーザーに対して、②ステータスコード 301を返し、リダイレクト先のURLをLocationヘッダーに記すことで、httpsのアクセスの方に強制させている。
しかしこの場合、①と②で行われる通信は平文で暗号化もされない状態となっているため、悪意を持った人間に通信内容を盗聴・改ざんされる恐れがある。
このような攻撃のことを「中間者攻撃」と呼ぶ。
HSTSは、Webサーバ側が「strict-transport-security」というレスポンスヘッダーをブラウザに送信することで、httpsアクセスに強制させる仕組み。
このstrict-transport-security ヘッダーというのは、ブラウザに「次回以降はHTTPの代わりにHTTPSを使うように」というような指示を表している。
ブラウザはその指示を受けて、自分の中にあるリスト内 (キャッシュ) にドメイン名を登録し、ユーザーが再びhttpでアクセスしてきたときは、ブラウザはWebサーバに問い合わせを送る前に、まず自分のキャッシュにそのドメイン名が存在するかどうかをチェックし、あればhttpをhttpsに変換してリクエストを送信する。
| HSTS設定なしの場合 | httpで通信 → httpsに301リダイレクト。毎回必ずhttp通信が発生する。 |
| HSTS設定ありの場合 | 初回だけhttp通信をすれば、以降は有効期限内であれば、301リダイレクトなしにhttpsでの通信になる。 |
DNSでIPアドレスを取得する
DNS(Domain Name System)は、IPアドレスとドメイン名の対応づけを行うシステム。
インターネットに接続している機器(PC、スマホ、サーバ、ルーターなど)には、必ず1つ1つに固有の番号が振られており、この番号を IPアドレス と呼ぶ。
インターネットで通信をするときは IPアドレスで相手を指定して通信を行う。
IPアドレスは、「10.11.12.13」のようにドットで区切られた数字になっているが、いちいち人間が「10.11.12.13」というような数字の羅列を覚えるのは不可能であるため、ドメイン名を入力すれば対応するIPアドレスが何かを教えてくれる仕組み=DNSが必要。
ブラウザのキャッシュを調べる
まずブラウザは、自分がIPアドレスを既に知ってるかどうか調べるために、自分自身のキャッシュを見に行く。アクセスしたのが最近だった場合、IPアドレスがキャッシュに残っている可能性がある。
もしキャッシュに残っていれば、名前解決のプロセスはこれで終了。
hostsファイルを調べる
ブラウザにキャッシュが残っていなかった場合、今度は hostsファイル を調べに行く。
hostsファイルとは、OSの設定ファイルの一つで、TCP/IPネットワーク上のIPアドレスとホスト名の対応を記述するテキストファイルのこと。
初期のインターネットでは、hostsファイルの原型である「HOSTS.TXT」というテキストファイルを用いて、ドメイン名をIPアドレスに変換する処理を行っていた。
hostsファイルの中身
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost上記で「127.0.0.1 localhost」とあるように、[IPアドレス] [ホスト名]というフォーマットで書かれる。
HOSTS.TXTが使われていた当時(1970年代)では、わずか数百台のホストしかなかったので、ネット上の全てのホスト情報の記載が可能だったが、インターネットが普及していくにつれてHOSTS.TXTは肥大化していき、1983年には、ホスト数はおよそ数万台となる。
もはやHOSTS.TXTによる名前解決は不可能となり、現在のようなDNSサーバを設置して名前解決する仕組みが生み出された。
名残のhostsファイルは現在も使われており、名前解決でDNSサーバに問い合わせる前に、ブラウザはhostsファイルを見に行き、もしファイル内に対象のホスト名があれば、そこで名前解決のプロセスは終了する。
スタブリゾルバを呼び出す
もしhostsファイルに対象の koooooootalogic.tech のIPアドレスがなかったら、DNSサーバに問い合わせる。
ブラウザはまず スタブリゾルバ というものを呼び出す。
スタブリゾルバとは、クライアントのPCの中にOSとして備わっている機能のことで、呼び出されたスタブリゾルバは、キャッシュDNSサーバに対して「koooooootalogic.techのIPアドレス知ってる?」と問い合わせを行う。
キャッシュDNSサーバ は名前の通り、各問い合わせの結果を一定期間キャッシュに保存しておいて、後で同じ問い合わせがきた場合は、その結果を再利用して返す。

そのため、以前にスタブリゾルバから「koooooootalogic.techのIPアドレス知ってる?」という問い合わせを受けていたら、キャッシュに保存されているはずなので、その問い合わせ結果をスタブリゾルバに返す。
スタブリゾルバは、受け取った結果からIPアドレスを取り出して、ブラウザから指定されているメモリー領域に書き込む。これで、名前解決のプロセスは終了。
もしキャッシュDNSサーバに koooooootalogic.tech の問い合わせ結果のキャッシュがなかったら、キャッシュDNSサーバは、スタブリゾルバの代わりに 「ルートネームサーバ」 → 「.techのネームサーバ」 → 「koooooootalogic.techのネームサーバ」 へと順に問い合わせを行う。

そして、IPアドレスが分かったら、スタブリゾルバに「IPアドレスがわかった」という問い合わせ結果を返す。スタブリゾルバは、問い合わせ結果からIPアドレスを取り出して、ブラウザから指定されているメモリー領域に書き込む。
これでブラウザは koooooootalogic.tech のIPアドレスをゲットできたので、名前解決のプロセスは終了。
IPアドレスを利用するときは、このメモリー領域からIPアドレスを抜き出してWebサーバにリクエストを送るという流れになる。
ポート番号
ポート番号 とは、TCP/IPにおいて、同じコンピュータ内で動作する複数のソフトウェアのうち、どれと通信するのか指定するための番号のこと。
ポート番号は、URLのドメイン名の 末尾 にコロン (:) と決められたポート番号を指定すれば、相手の指定ができる。
たとえば http://example.com/ の場合は、http://example.com:80/というような感じ。
koooooootalogic.tech の場合は、HTTPSなのでhttps://koooooootalogic.tech:443/と指定する。
私たちがブラウザでURLにポート番号を入力しなくてもWebサイトにアクセスできるのは、スキームを見て「http:」だったら80番、「https」だったら443番というように、自動的にポートを割り当てているから。
HTTPリクエストの送信
HTTPリクエスト とは、ブラウザからWebサーバへ送信される要求のこと。
「URLを解読する」でドメイン名とパス名が判明したので、ブラウザはそれを元にHTTPリクエストを作成する。
HTTPリクエストは「リクエストライン」と「ヘッダー」と「メッセージボディ」というフォーマットで作成される。
GET / HTTP/2
Host: koooooootalogic.tech
User-Agent: curl/7.64.1
Accept: */*実際にはこのリクエストのあとに、レスポンス内容も続けて出力されているが、それは次の「HTTPレスポンスの送信」で触れる。
リクエストの構成を図で表すと、以下のようになる。
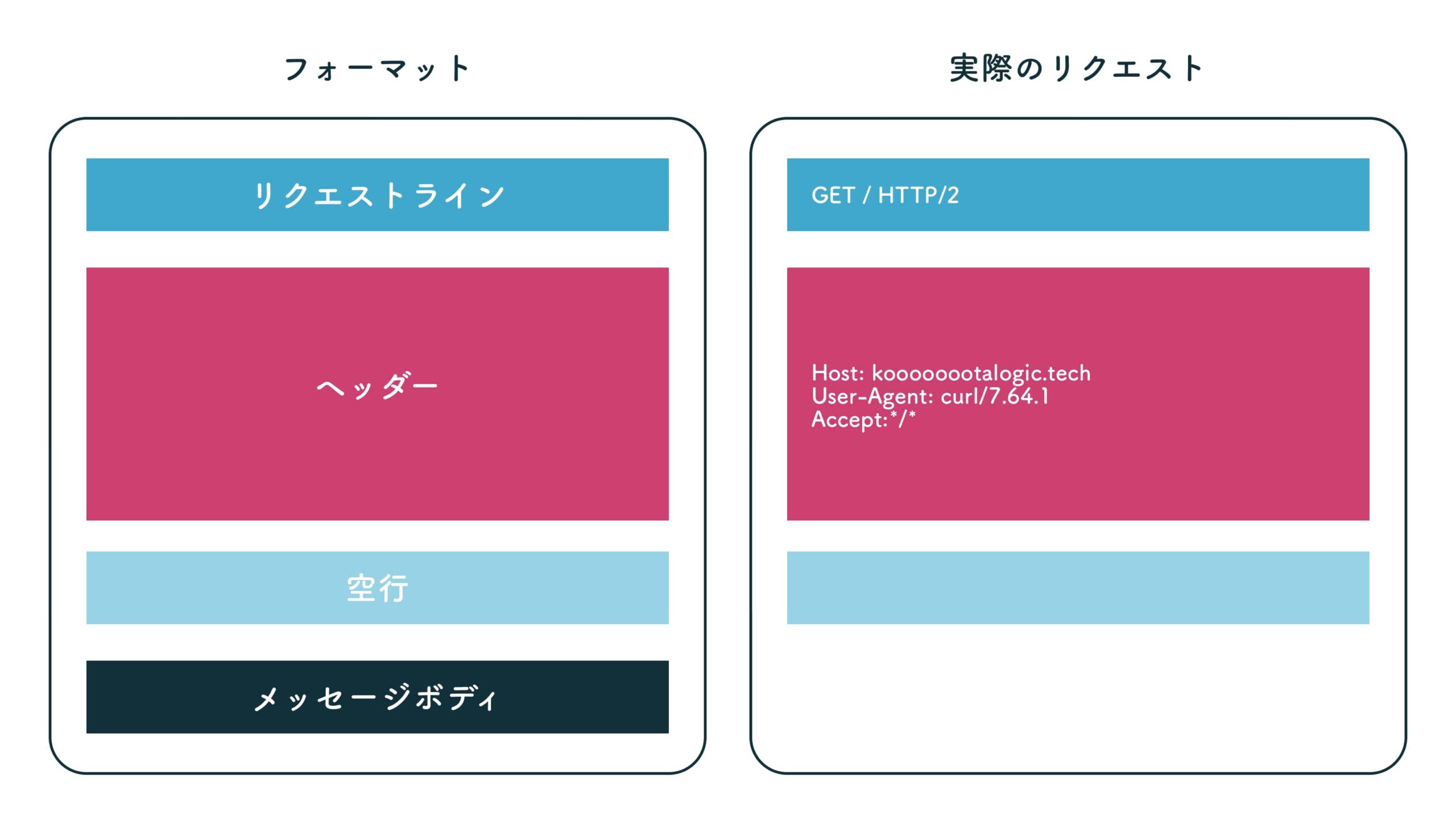
この中で、一番大事なのは1行目のリクエストラインである。
GET / HTTP/2 は、左端からそれぞれ「HTTPメソッド」「リクエスト先のURI」「HTTPのバージョン」のことを指す。
GET は最も一般的に使用されるメソッドで、ブラウザがWebサーバに対してページの取得を要求することを表す。どのページを要求しているかというのは、左から2番目に書かれた / のこと。これはURLの中に埋め込まれているパス名からそのまま書き写される。
また、フォーマットが「リクエストライン」と「ヘッダー」と「メッセージボディ」であるのに対して、実際のリクエストではメッセージボディが存在しないのは、HTTPメソッドが GET だから。GET の場合は、メソッドとURLだけでWebサーバは何をすべきか判断できるので、メッセージボディに何かを書く必要は無い。
ロードバランサー
ロードバランサー とは、Webサーバにかかる負荷を複数に分散させるための装置。「負荷分散装置」とも呼ばれる。
Webサービスにおいて、1台のサーバのみで運用するとアクセス集中でサーバがダウンしたときなど、サービス停止に追い込まれてしまうので、複数サーバを用意するのが一般的。
ロードバランサーは、これら複数台のWebサーバを束ねて、Webサーバに来たリクエストをバランス良く振り分ける装置のことを言う。
ロードバランサーの有能な機能として、サーバの状態を把握する ヘルスチェック と、同じクライアントのリクエストを継続的に同一のサーバに振り当てる セッション維持 というのがある。
配下にあるWebサーバが正常に稼働しているかどうかを常にチェックする機能。もし正常に応答を返さなかったら「異常」だと判断して、そのサーバに対してはリクエストを割り振らず、別の正常なサーバに割り振る。
同一ユーザーからのアクセスは同じサーバに振り分ける機能。
これがないと、ログインをしても、その次の通信でロードバランサーが別のサーバにリクエストを飛ばしてしまったときに、サーバは前の通信状態を知らないので、ログインが途切れてしまう。
なので、送信元のIPアドレスをチェックするなどの方法で、同じユーザーからのアクセスは、同じサーバに振り分けます。
また、同じクッキーを持つ通信は必ず同じWebサーバに振り分けるクッキーによるセッション維持の方法もあります。
HTTPレスポンスの送信
リクエストを送ると、Webサーバからはレスポンスが返ってくる。
「HTTPリクエストの送信」で省略していたHTTPレスポンスの中身は、以下のとおり。
HTTP/2 200
etag: "de7-OJQMWJz+xf8wsmQufuQRjAHeH+c"
content-type: text/html; charset=utf-8
accept-ranges: none
vary: Accept-Encoding
x-cloud-trace-context: 0a770f14325a57bd2fca0a614fd11841;o=1
date: Mon, 08 Mar 2021 15:17:31 GMT
server: Google Frontend
content-length: 3559
<!doctype html>
<html >
<head >
<title>koooooootalogic.tech</title>
...
</head>
<body >...</body>
</html>この構成を図で表すと、以下のようになる。

リクエストと違って、レスポンスの1行目は ステータスライン と言う。HTTP/2 200 というのは、それぞれ「HTTPのバージョン」と「ステータスコード」を表す。
ステータスコード というのは、リクエストが成功したのかエラーが起きたのかを表すコード。この場合は 200なので、Webサーバの処理が無事成功したことを表している。
また、ヘッダーの中には content-type: text/html; charset=utf-8 というものが記載されている。
メッセージボディに入っているデータが、どのような形式なのかを示すもので、この場合「コンテンツはHTMLファイルであり,その文字コードはUTF-8である」ことを表している。ブラウザはこれを見て、データをどのように処理するかを判断する。
メッセージボディには、content-typeで記載されたとおり、リクエストしたリソースであるHTMLが格納される。レスポンスが返ってきたら、メッセージボディからデータを取り出して、ブラウザに表示させる。
HTMLのレンダリング
レンダリングの大まかな流れは以下の通り。

描画に必要なHTML、CSS、JavaScript、画像などのリソースを読み込む。
このとき一番最初に取得されるリソースは、HTMLファイル。
ブラウザはこのHTMLファイルを上から順に読み込んでいって、途中でCSSやJavaScriptや画像などの外部のリソースを発見したら、Webサーバにその都度問い合わせてリソースを取得する。
字句解析 → 構文解析 → コンパイルという処理が終わって、はじめてJavaScriptのコードが実行される。
JavaScriptのコードの中にAPI呼び出しの処理があった場合、APIサーバにリクエストをしてデータの取得を行う。
読み込んだリソースは、レンダリングエンジンの内部リソースに変換され、HTMLはDOMツリーに、CSSはCSSOMツリーにそれぞれ変換される。これらは後続のフェーズであるレンダーツリーの構築やペインティングで利用される。
- DOM(Document Object Model)とは
各HTMLの要素の関係を表すDOMと、HTMLの要素にどんなスタイルを当てるかを表すCSSOMを合わせてレンダーツリーを構築する。
レンダーツリーはページのレンダリングに必要なノードのみで構築される。

例えば、上記のCSSOMでは body > p > span の要素に display: none というスタイルを適応している。このスタイルは「画面上で非表示にする」というものなので、レンダーツリーの構築の際には除外される。
また、DOMに含まれている <html> と <head> も画面上では視覚化されないので、こちらもレンダーツリーからは除外される。
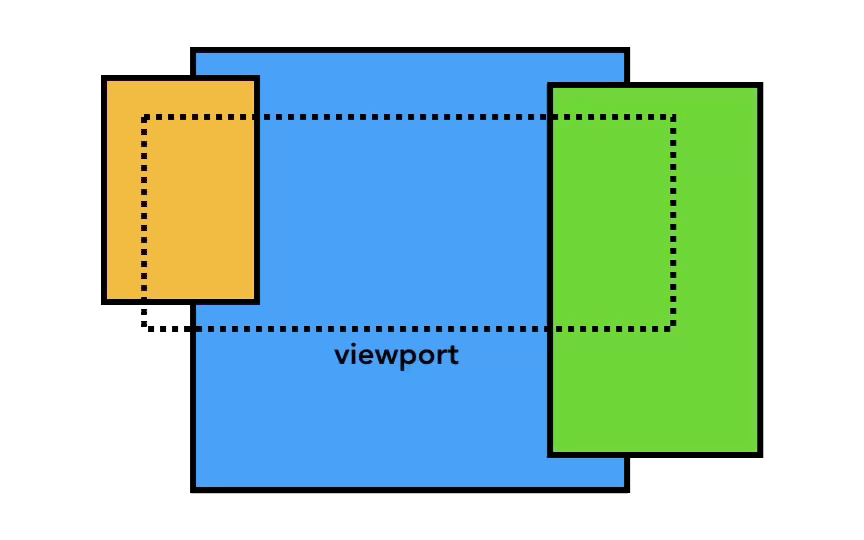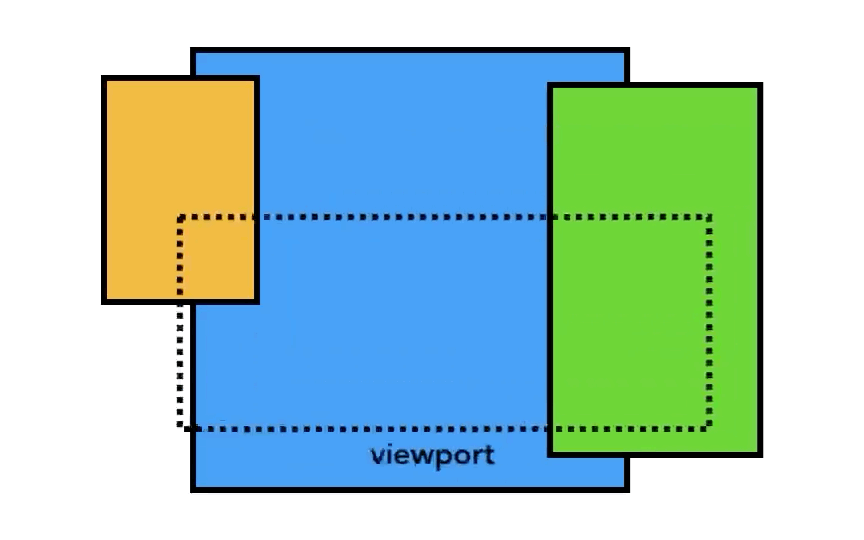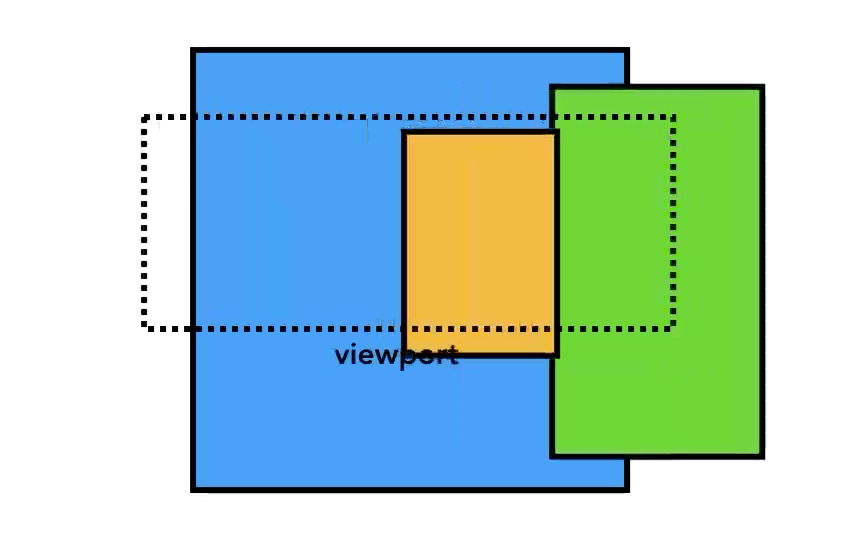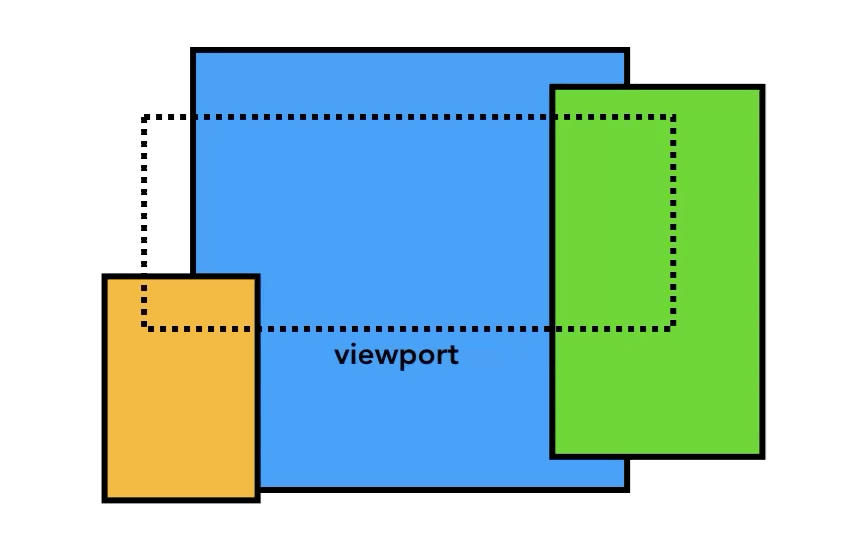
レンダーツリーが構築された後、ブラウザはviewport内でのノードの正確な位置やサイズなどを計算する。このステップをレイアウトと呼ぶ。
viewport(現在表示されている領域)のサイズは、head内の <meta name="viewport" …> での指定によって決まる。
<!DOCTYPE html>
<html>
<head>
<!-- ここでサイズを指定 -->
<meta name="viewport" content="width=device-width" />
</head>
<body style="background-color: orange">
<div style="width: 50%; background-color: blue">
<div style="width: 50%; background-color: yellow">Hello!</div>
</div>
</body>
</html>上記の場合は、content に "width=device-width" という値を指定しているので、viewportの幅は 端末の画面幅と等しく なる。
ブラウザはviewportのサイズを見て、各要素のサイズや配置場所などを決めていく。
上記のHTMLの場合 <body> の中に2つの <div> があり、サイズを決める際、親の方の <div> は viewport 幅の50%に設定する。子の <div> は親の50%、つまりviewport幅の25%になる。
レイアウトの計算が終われば、レンダリング結果の描画に移る。
順番を決めずに描画してしまうと、要素に z-index が設定されていた場合など、要素の重なりが考慮されない画面になってしまうため「Paint Records」と呼ばれるものを作成する。
このPaint Recordsの順番は、Stacking Contextに要素がスタックされる順番と同じになる。具体的には以下のような順番。
- background color
- background image
- border
- children
ペイントする順番が決まれば、これまでの情報をもとに画面上のピクセルに変換する。これを「Rasterize」と呼ぶ。
- Rasterizeのプロセス
ブラウザはレイヤーごとに Rasterize を行っていく。どの要素がどのレイヤーにあるべきか知るために、ブラウザは以前構築したレンダーツリーを見て「 レイヤーツリー (Layer Tree) 」と呼ばれるものを新たに作成する。ここまでの処理はブラウザの「Main Thread (メインスレッド) 」上で行われる。
描画する順序が決まり、レイヤーツリーの作成も終わったので、Main Thread はこれらの情報を「Compositor Thread (コンポジタースレッド) 」に託す。Compositor Thread は、レイヤーツリーの各レイヤーごとにピクセル単位で色を当て込む。
レイヤーの大きさはそれぞれだが、ページ全長のように大きなサイズになる可能性があるため、Compositor Thread はレイヤーをタイルのように小さく分割して、各タイルを「Raster Threads ( ラスタースレッド ) 」に送信する。
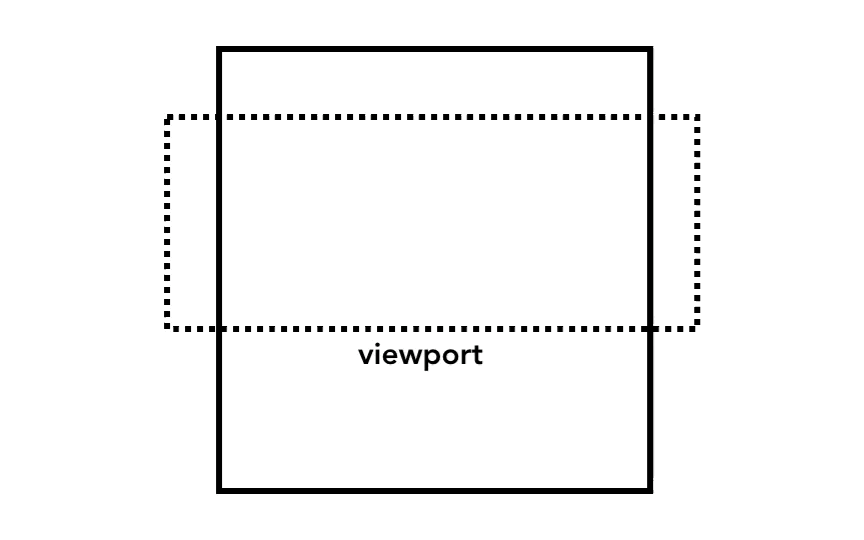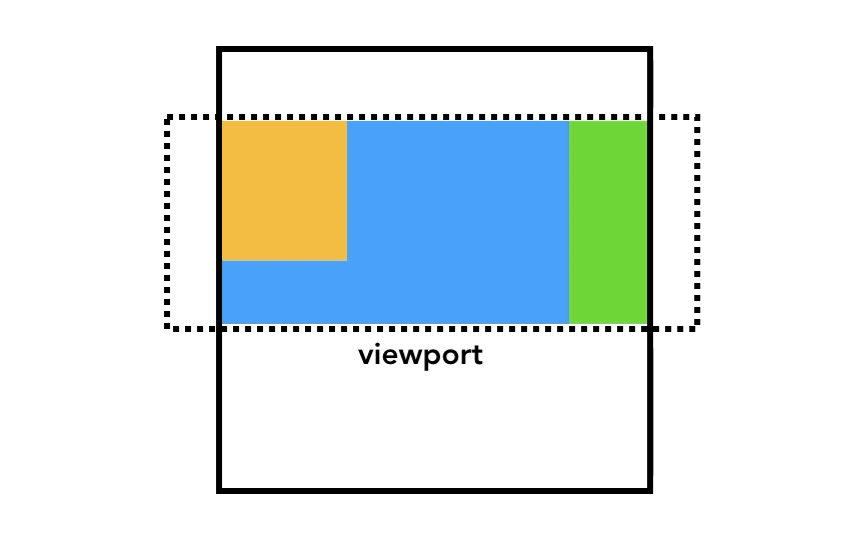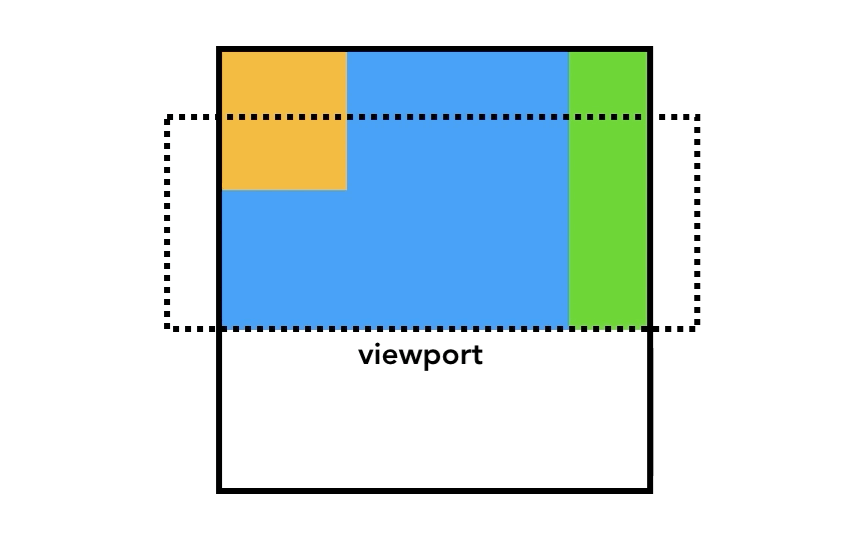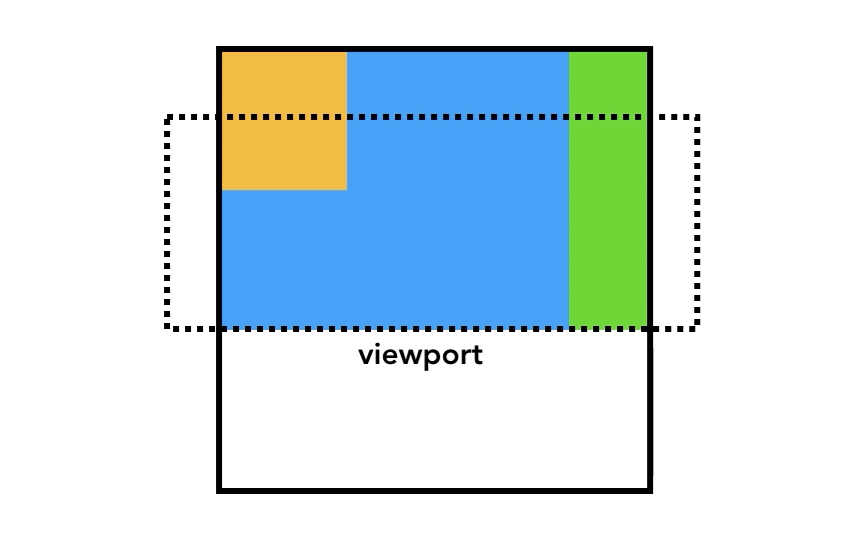
viewport 内のものを最初に描画できるように、Compositor Thread は Raster Threads に優先順位を付けることができる。
完了したら、Compositor Thread はそれらを集約し、「Composite Layers」を作成する。そして、この Composite Layers をGPUに送り、最終的に画面に描画することができる。
コアウェブバイタルを意識したCSS・レイアウトの構築
CSSの記述方法やレイアウトの構築方法は、コアウェブバイタル(Core Web Vitals)に大きな影響を与える。特にCumulative Layout Shift (CLS) と Largest Contentful Paint (LCP) に当てはまる。
| Cumulative Layout Shift (CLS) | ページの読み込み時に発生するレイアウトのずれ、視覚的な安定性を測定する指標 |
| Largest Contentful Paint (LCP) | ページの表示速度、読み込みにかかる時間を測定する指標 |
| First Input Delay(FID) | アクションを起こした時の反応の速度、インタラクティブ性を測定する指標 |
DOMへのコンテンツ挿入
周囲のコンテンツがすでに読み込まれた後にコンテンツを挿入すると、ページ上の他のすべてが押し下げられる。これにより、レイアウトシフト(レイアウトのずれ)が発生する。
例えば、Cookieの通知パネル。特にページの上部に表示される通知パネルは、この問題の一般的な例。
他にも広告や埋め込みなどの要素が読み込まれる際に、このようなレイアウトシフトを引き起こす。
- 修正方法
画像によるレイアウトシフトのCSSを改善
ブラウザは、画像が読み込まれて初めて画像のサイズを決定できる。
ページがレンダリングされた後に画像の読み込みが行われた場合、画像用のスペースが確保されていないと、画像が表示されたときにレイアウトシフト(レイアウトのずれ)が発生する。
補足: レイアウトシフトを引き起こす画像の現象は、画像の読み込みが遅い状況でより明白になる。例えば、接続が遅い場合や、ファイルサイズが特に大きい画像を読み込む場合など。
- 修正方法
WebフォントのCSSを改善
Webフォントは、テキストのレンダリングを遅らせたり、レイアウトシフトを引き起こす原因となる。
そのため、フォントを迅速に提供することが重要となる。
テキストレンダリングの遅延
デフォルトでは、ブラウザは使用するWebフォントがまだ読み込まれていない場合、テキスト要素をすぐにはレンダリングしない。これは、「スタイルなしテキストの点滅(FOUT)」を防ぐため。多くの場合、これはFirst Contentful Paint(FCP)を遅らせることになる。場合によっては、Largest Contentful Paint(LCP)も遅らせることになり得る。
補足: デフォルトでは、ChromiumベースとFirefoxのブラウザは関連するWebフォントが読み込まれていない場合、テキストのレンダリングを最大3秒間ブロックする。(Safariは無期限にブロックする)ブロック期間は、ブラウザがWebフォントを要求したときに始まり、ブロック期間が終了してもまだフォントが読み込まれていない場合、ブラウザはフォールバックフォントを使ってテキストをレンダリングし、使用可能になるとWebフォントにスワップする。
Webフォントによるレイアウトシフト
フォントのスワップ(入れ替え)は、コンテンツをユーザーに素早く表示するのに優れているが、一方でレイアウトシフトを引き起こす可能性がある。レイアウトシフトは、Webフォントと予備フォントがページ上で異なるスペースを占めるときに発生する。似たような比率のフォントを使用することで、このようなレイアウトシフトを最小限に抑えることができる。
- 修正方法
クリティカルCSS
スタイルシートはレンダリングをブロックする。ブラウザが読み込む際にスタイルシートに遭遇し、ブラウザがスタイルシートをダウンロードして解析するまで、他のリソースのダウンロードを停止する。
これにより、LCPが遅延する可能性がある。
パフォーマンスを向上させるためには、未使用のCSSを削除し、重要なCSSをインライン化し、重要でないCSSを延期することを検討する。
レスポンシブデザインのコーディングテクニック
ブレイクポイントは特定のデバイスの画面サイズを基準にしない
- 主流のデバイスのサイズなんてものは時間が経てば変化する。
- 主流のデバイスを贔屓して設計を最適化しても、別のデバイスでは窮屈だったりゆとりが余りすぎている…という場合も多い。多くの小画面カンプがiPhoneに合わせて 375px で作られているがAndroid の多くは 360px である。
- 短期公開の LP やディザーサイトならまだしも、長期的に運用される Web サイトにおいては流行りの端末に左右される設計は致命的。
出回っている数多くの画面幅に対応し、さらには縦持ち・横持ちなども考慮したら、考えられる最小の画面幅から最大の画面幅まで全ての環境である程度最適化された見た目を実現するのが理想なのは間違いない。レスポンシブデザインは一つの寸法で 100 点を目指す思想ではなく、より多くの寸法で 90 点が出るように最適化する思想である。特定のデバイスを意識したブレイクポイントの決定はこの思想と相反してしまう。
ブレイクポイントは予め定数として用意しておくと良い
理想としてはデザインごとに最適なブレイクポイントを探して決定したほうが良いのだが、デザインごとに最適なブレイクポイントを探るのは非常に難易度が高い。
デザインカンプで表現されるのは「あくまでその画面幅での見た目」なだけであって、そのデザインの最適なブレイクポイントを紐解くためにはカンプで表現されていない部分に目を向ける必要がある。
そのため、デザインごとの最適なブレイクポイントを見つけ出すためにはデザイナーとの細かい認識合わせが必要になる。一方で、締切・納期というものがある以上デザイナーとのやり取りに多く時間を掛けられないのが現実。
そういった事情から、予めある程度の的確な位置・間隔でブレイクポイントを用意しておくほうがやりやすい。実装者側からデザイナーに「ブレイクポイントはこのようにしていきたい」と働きかけたほうが良い。
- ある程度の的確な位置・間隔で打ち決めされていればブレイクポイントは何でも良い。
- おすすめのブレイクポイントは次の 2 パターン。パターン 1 はBootstrap 5を、パターン 2 はTailwind CSSのそれを参考にしている。
$breakpoints: (
'sm': (min-width: 576px),
'md': (min-width: 768px),
'lg': (min-width: 992px),
'xl': (min-width: 1200px),
'xxl': (min-width: 1400px)
) !default;$breakpoints: (
'sm': (min-width: 640px),
'md': (min-width: 768px),
'lg': (min-width: 1024px),
'xl': (min-width: 1280px)
) !default;変数の命名は抽象的にする
変数の命名は抽象的にしておき、sp, tb, pc のようにデバイスを連想させないようにする。これはレスポンシブごとのユーティリティクラスを作る上でも同じ。ブレイクポイントが増えた場合にそれらに対して具体的な命名をするのは難しいため、相対的な名前にするほうがベター。
ブレイクポイントは少ないほうがメンテナンス面では良いのだが、デザインによっては 2 つ 3 つでやりくりするのは非常に辛い。特に 1024px 付近は癖が強いため、最低でも 4 つほど保険として用意しておいたほうが良い。保険として複数用意した上で、なるべくブレイクポイントを少なく抑える努力をすれば良い。
360px 未満は JS で viewport を固定する
4 インチ対応(320px 対応)はこの先も必須であることは間違いないのだが、実装コストの割にリターンが小さいため、 360px 未満は JS で viewport を書き換える方針を推奨する。
!(function () {
const viewport = document.querySelector('meta[name="viewport"]');
function switchViewport() {
const value =
window.outerWidth > 360
? 'width=device-width,initial-scale=1'
: 'width=360';
if (viewport.getAttribute('content') !== value) {
viewport.setAttribute('content', value);
}
}
addEventListener('resize', switchViewport, false);
switchViewport();
})();前提として 375px 付近で作られるデザインをそのまま実装したら 4 インチでほぼほぼ崩れると言っても過言ではない。そのため、4 インチ対応する場合は 4 インチでどう見せたらいいか?をデザイナーと細かい認識合わせした上で 4 インチを意識した実装を行うことになり、実装コストがそこそこ掛かるのが実情。
statcounter のデータによれば 4 インチ端末のシェアは(2021年2月時点では)日本国内のモバイル全体における 2.93%と減少傾向にある。約 3%は決して無視して良い数値ではないのだが、昨今の画面サイズの大型化の流れで、シェアの減少は続くだろう。
iPad の Slide Over およびに Split View の論理サイズは 320px なので現在 4 インチを意識したコーディングをする必要がある理由はここにあるのだが、前述した実装コストに対して見返りが釣り合っていないという意見もある。
加えて、画面幅が 300px 以下の端末が登場したことも理由の一つである。
- 折りたたみスマートフォンの Galaxy Fold の一部の画面幅はまさかの 280px。
- Galaxy Fold 自体は2019年の時点で世界で 100 万台出ているものの、日本国内においては流通量は少ない。ただ、将来どうなるかは分からないし、折りたたみスマートフォンが国内においてもシェアが広がり 280px 相当の画面幅がマイナーではなくなる…という未来が訪れる可能性は 0 とは言い切れない。
- また、「Galaxy Fold lang:ja」で Twitter 検索したら分かるように Galaxy Fold を愛用している国内ユーザーは想像以上に多い印象。
- さらに言うと、広げた状態のマルチ状態だと画面幅は 229px まで狭まるらしい。
以上の理由から 360px 未満は JS で viewport 書き換えで対応とするのがベターだという結論に達した。
- 将来どんな極狭画面サイズが来ても JS 無効にされなければ安心。前述した 229px 相当の画面幅でもスケーリングされる関係で相当読みづらくなるが、そこはピンチアウトしていただく方向で。レイアウトが崩れるよりかは大分マシだろう。
- Android の標準サイズが 360px なので、そこまではスケーリングしないで対応したい。
- もちろん JS 無効環境を考慮してもできる限り 4 インチで見られても崩れないようなコーディングをしたほうが良いのは言うまでもない。
ちなみに、vw ベースで組んでいる場合は JS で viewport を書き換える必要はない。
モバイルファースト(min-width)で書く
スタイリングはシンプルなものを基準として上書きしていったほうが無駄がない。
- レスポンシブデザインにおいてはビューポートが狭ければ狭くなるほど画面構成がシンプルになる場合が多い。
- 最小のビューポートを基準とし、順に画面を広げて設計したほうが継承を促しつつ最小限のスタイルの上書きをすることができるようになるため都合が良い。
- 一方、最大のビューポートを基準とし、順に画面を狭めて設計すると
display:flex→blockなど初期値での上書きが必要になったりして無駄が多くなりがち。 - 原則的にはメディアクエリの指定は min-width を使い、max-width は避けて書くのがベター。
もし、ミディアムサイズなどで一時的に max-width を用いたい場合は未満を表す方法には注意して書いたほうが良い。
モバイルファーストで指定しているけれど、一部だけ 1024px 未満全体に当てたいスタイルがある場合は安易に max-width を用いるのではなく@media not all and (min-width: 1024px)のようにnot キーワードと min-width を組み合わせて指定することを推奨する。
@media (max-width: 1023px) {
/* 1024pxから1px引いて未満とするのは違う */
}@media (max-width: 1023px) @media (min-width: 1024px)のように記述すると、ブラウザの拡大率および解像度との組み合わせ次第で画面幅が 1023px と 1024px の間の状態になった場合にスタイルが当たらなくなったり意図しない現象が起こる可能性があるため。
@media not all and (min-width: 1024px) {
/* 1024pxを含まずそれより小さいという表現ができる */
}min-width を利用して書く都合上、スモールサイズのカンプからコーディングしたほうが効率が良いが、広い画面から矛盾なく狭い画面を逆算できるスキルを持っていればラージサイズのカンプからコーディングしても問題ない。
レスポンシブで画像を切り替える場合は picture 要素を使う
よく CSS で画像の切り替えを行っている例を見かけるが、picture 要素を使って出し分けたほうが良い。
<img class="pc" src="/assets/img/home/img_about_pc.jpg" alt="">
<img class="sp" src="/assets/img/home/img_about_sp.jpg" alt=""><picture>
<source srcset="/assets/img/home/img_about_md.jpg" media="(min-width: 768px)">
<img src="/assets/img/home/img_about_sm.jpg" alt="">
</picture>CSS でdisplay:noneしてもコンテンツはダウンロードされるため、CSS で画像の切り替えを行うと不必要な画像の読み込みが発生してパフォーマンス面に影響する。
picture 要素を利用して出し分ければ必要な画像のみが読み込まれるためパフォーマンス的に良い。
picture 要素を利用する際の注意点
- picture 要素の中には必ず 1 つの img 要素を含める必要がある。この img 要素は source 要素で利用可能な画像を提供できなかった場合の代替として用いられ、picture 要素そのものが非対応のブラウザで表示されることに留意。
- 画像の寸法、alt 属性、decoding 属性および loading 属性などは picture 要素内の img 要素に記述する。
- img 要素は source 要素の後に配置する。
- img 要素にはレイアウトシフトを防止するために width 属性と height 属性を指定しておくことが望ましいが、picture 要素で違う縦横比の画像を出し分ける場合は現時点では width 属性と height 属性を指定しないようにする。
- IE11 と Android4 系は picture 要素に対応していないので、これらが対応範囲である場合は Picturefill.js を導入する必要がある。
ブレイクポイントを跨いで共通化が難しそうな場合は無理に 1 ソースにまとめる必要はない
レスポンシブにおいては HTML は 1 ソースにすることが理想であるが、グローバルナビゲーションのように小画面ではポップアップ式で大画面では固定して横並びといったようにレスポンシブで仕様が大きく変化するものだったり、デザイナーがレスポンシブをあまりよくわからなくて荒業を使わないと HTML の共通化が難しい場合などは無理に 1 ソースにまとめるのではなく分けて管理したほうが良い。
HTML のリファクタリングよりも CSS のリファクタリングのほうが圧倒的に難しいため、保守性や拡張性を意識したら HTML 側を妥協するほうが将来的には良い。もちろん 1 ソースで管理することを第 1 に考えて、難しそうなら妥協するという考えで。
transition の all 指定は避ける
transition で all 指定しているとブレイクポイントを跨いだ時に意図しないアニメーションが起こる場合がある。例えば hover を伴うボタンの padding の値がブレイクポイントを跨いで変化する場合、ブレイクポイントを跨いだ時に padding にアニメーションが走ることになって見栄えが悪くなる。
面倒でも transition を指定する際はプロパティ名を記述するようにする。
.foo {
transition: all .3s ease-out;
}
.bar {
transition: .3s ease-out; /* transition-propertyの初期値はallなので注意 */
}.foo {
transition: opacity .3s ease-out;
}
.bar {
transition: background-color .3s ease-out, transform .3s ease-out;
}ブレイクポイント云々抜きにしても、ブラウザによっては読み込み時に意図しないアニメーションが起こったり、z-index などが transition 対象に含まれたりするとアニメーション時に意図しないバグが起こり得るため、all 指定は原則避ける方向性で良い。